
Adapting Large Language Models for Customer Request Handling: An exploration of possible approaches
Katsiaryna Mlynchyk, Alexandros Paramythis
Challenge
“Adapt” LLMs to the domain at hand, and to the factual knowledge of the individual company / organization for automated handling of customer requests – received through channels such as email, chat, social media, etc.
Such models will need to have access, in one way or another, to privileged, non-public information in the company’s knowledge base.
Requirements
- can be trained / fine-tuned / otherwise adapted with reasonable resources
- can be prepared and used on-premise, to avoid sending private information outside the company’s infrastructure
- must support the language in use
Exploration of possible approaches
Watch the video of our presentation at SwissText 2023, in which we present in brief different approaches of evaluating LLMs and their potential to “adapt” to the domain at hand. Alternatively, you can browse through the presentation slides that follow below.
Big picture
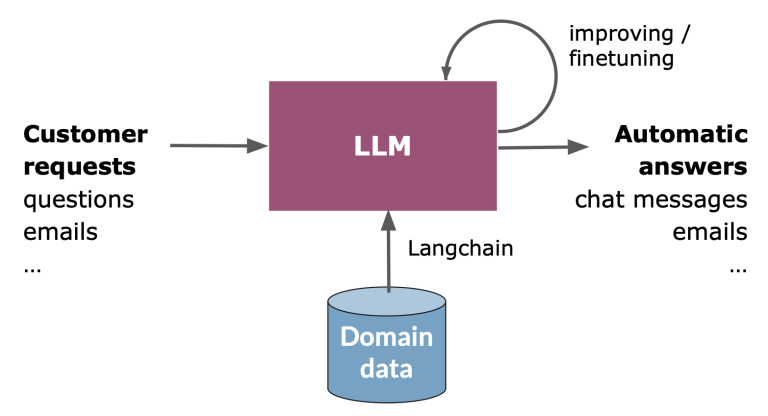
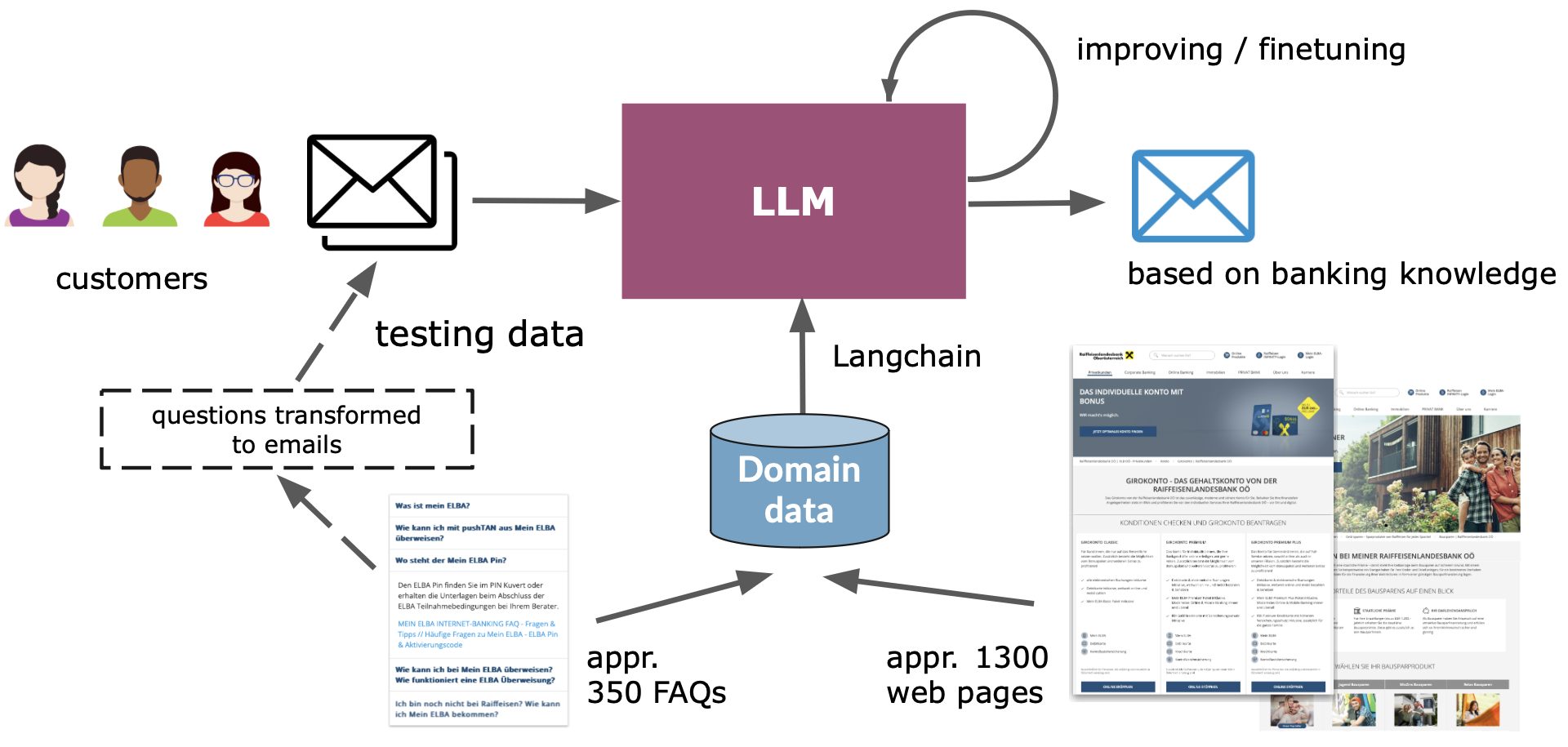
Banking Use Case: Raiffeisenlandesbank OÖ
General data
- Dolly v2
- 15k instructions translated to DE
- Open Assistant
- 4k “chat trees” either originally in DE, or translated to DE
- Translated datasets (will be made available on Hugging Face after SwissText)
- Get in touch to receive a notification: paramythis@contexity.ch
Project-specific data
- FAQs
- Web site content
- Test emails
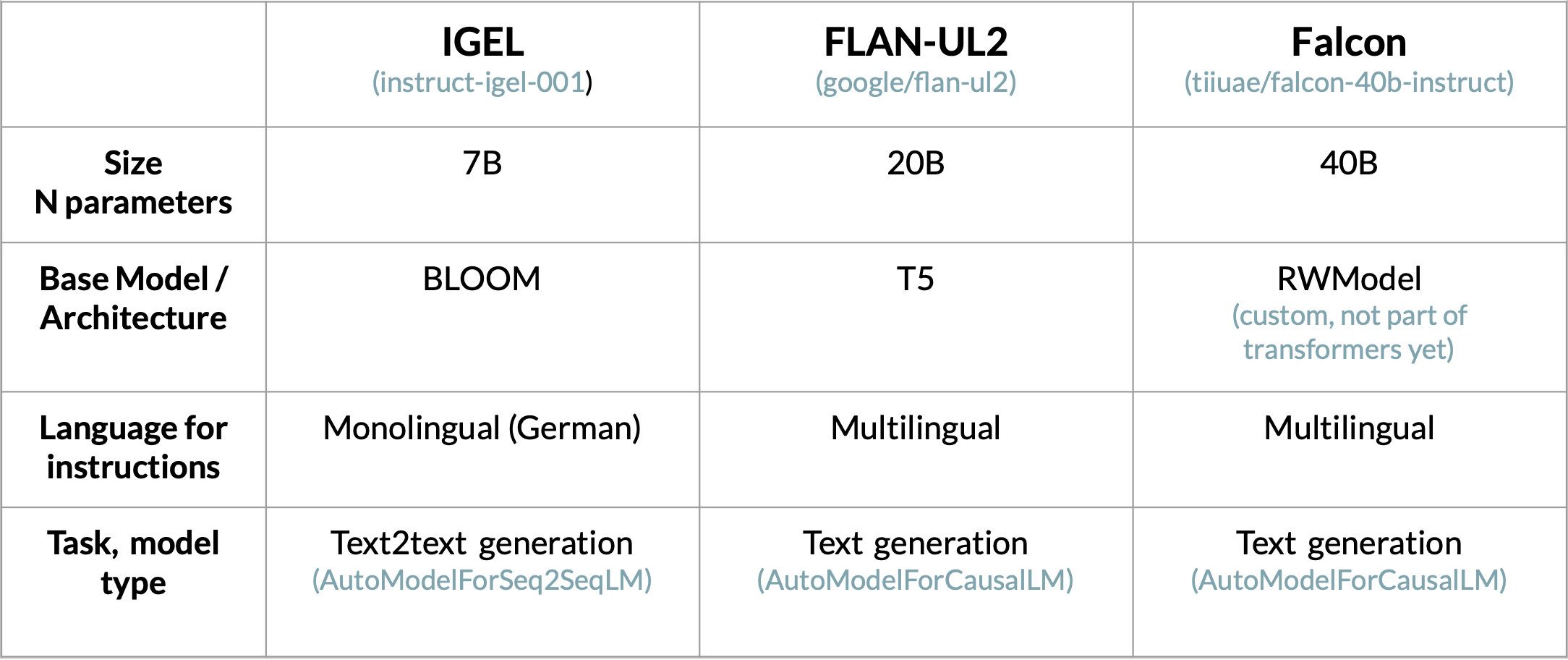
Considered models
Simple QA
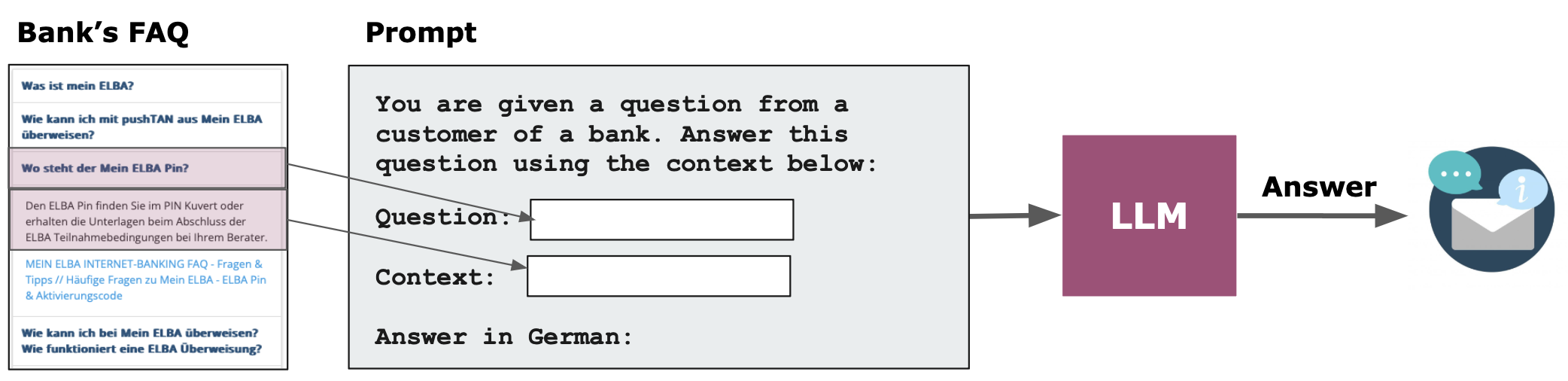
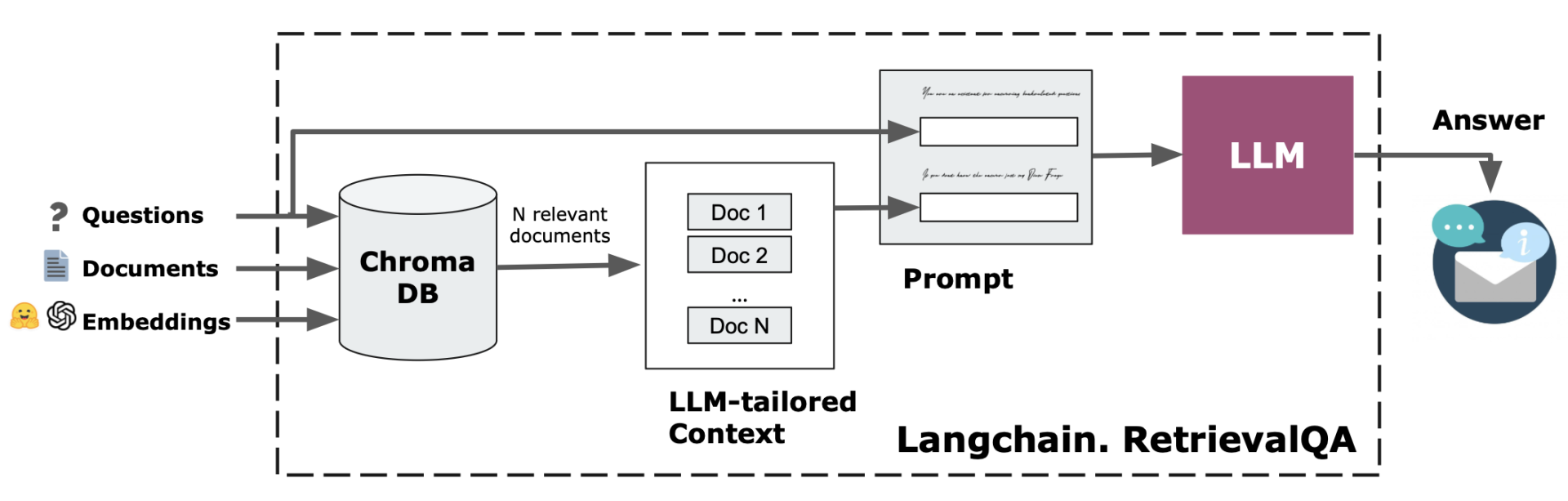
Process chain for QA (over FAQ / over all web data)
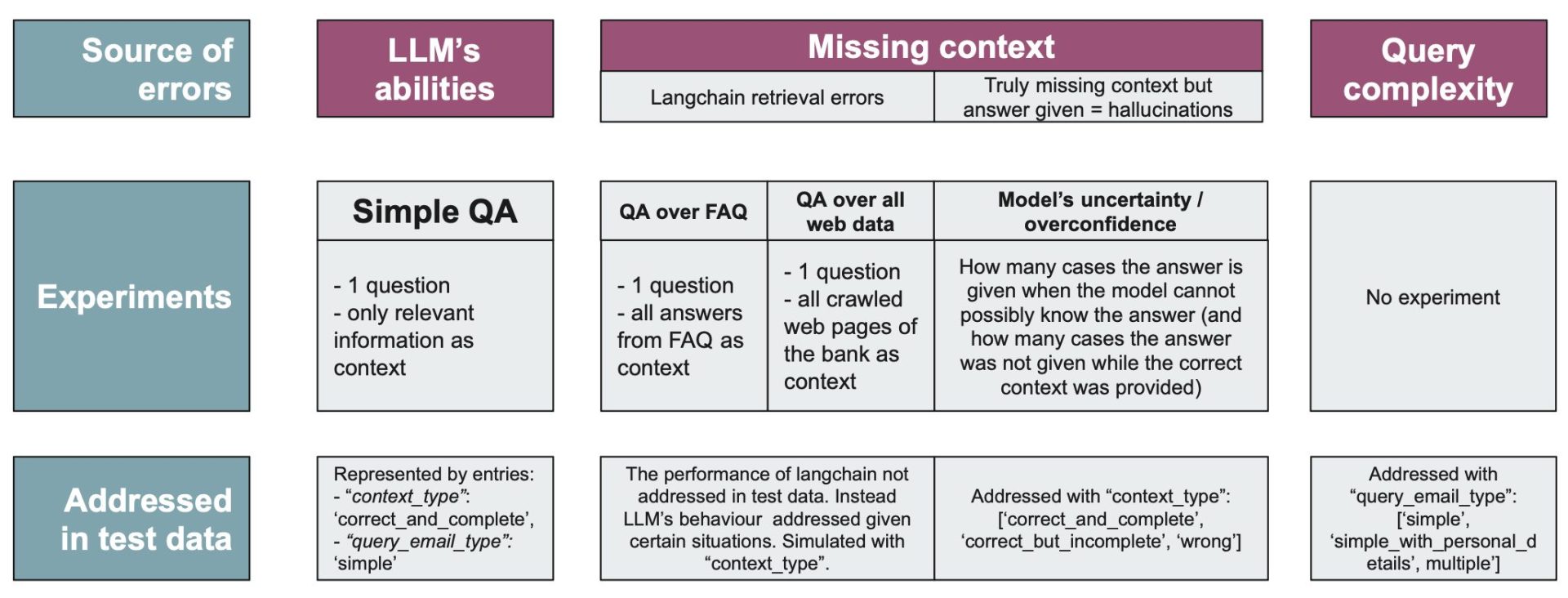
Possible sources of errors and their investigation
Test email generation

Evaluation & Results
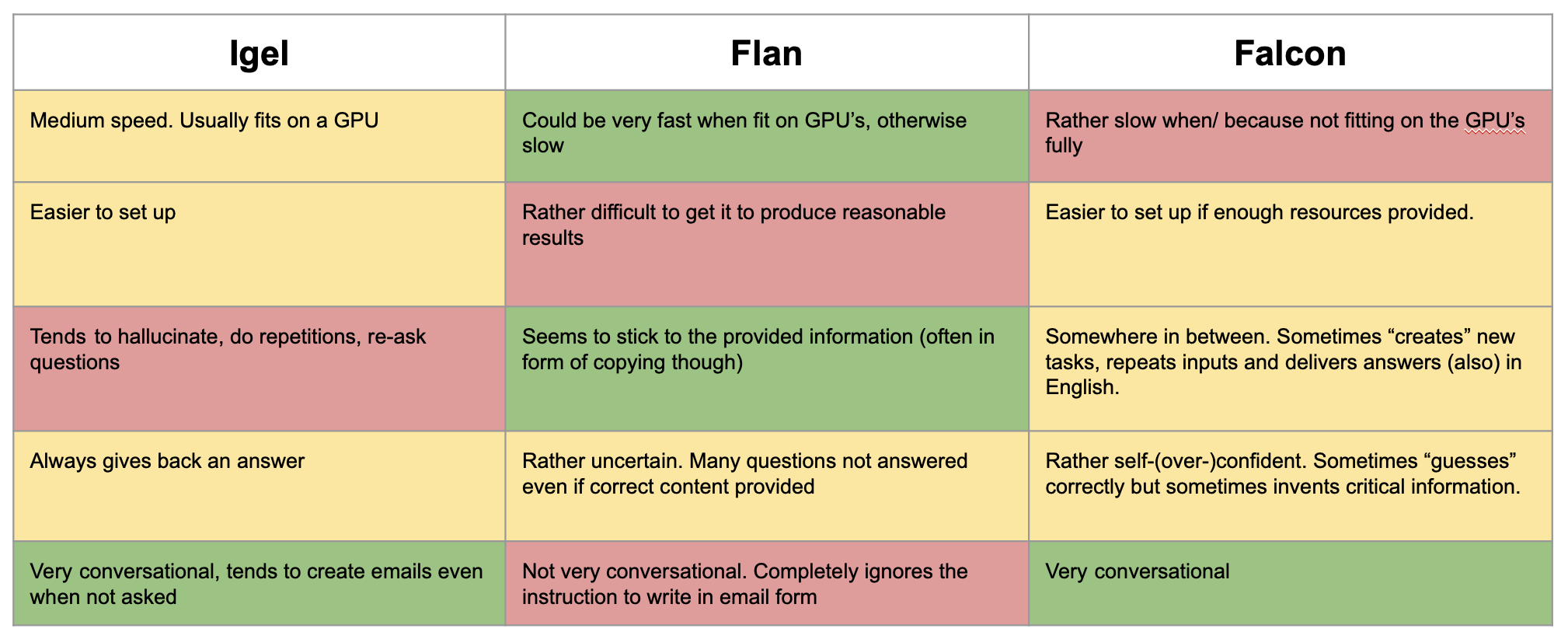
Comparison from tests with “given context”
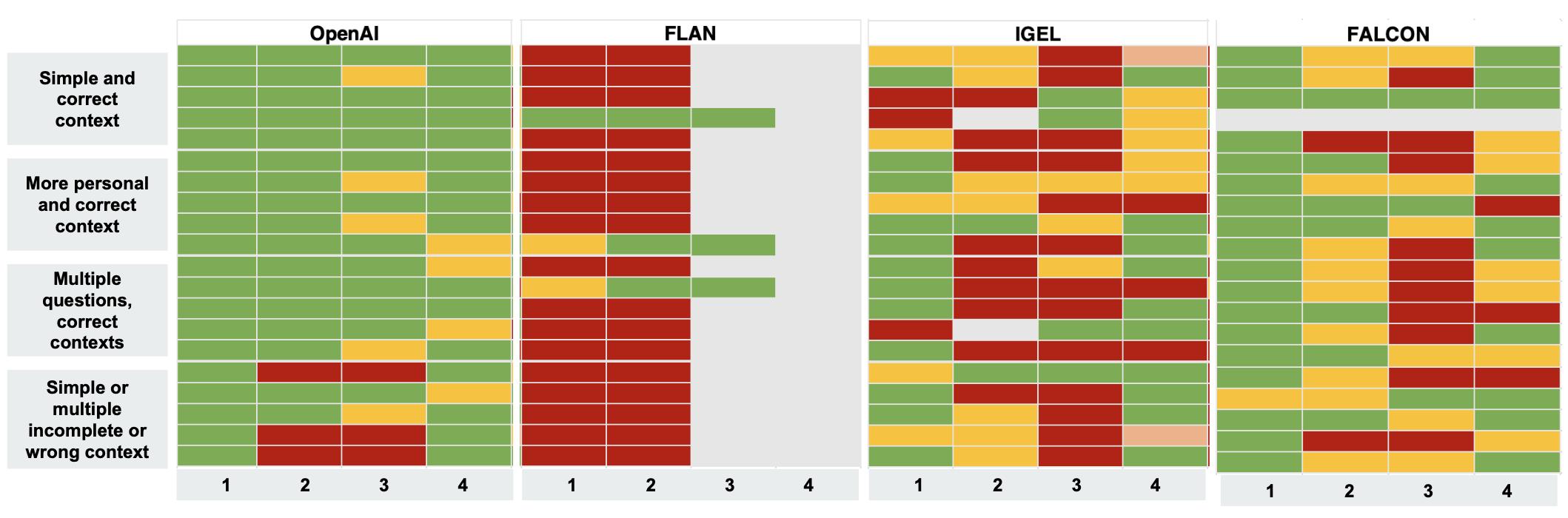
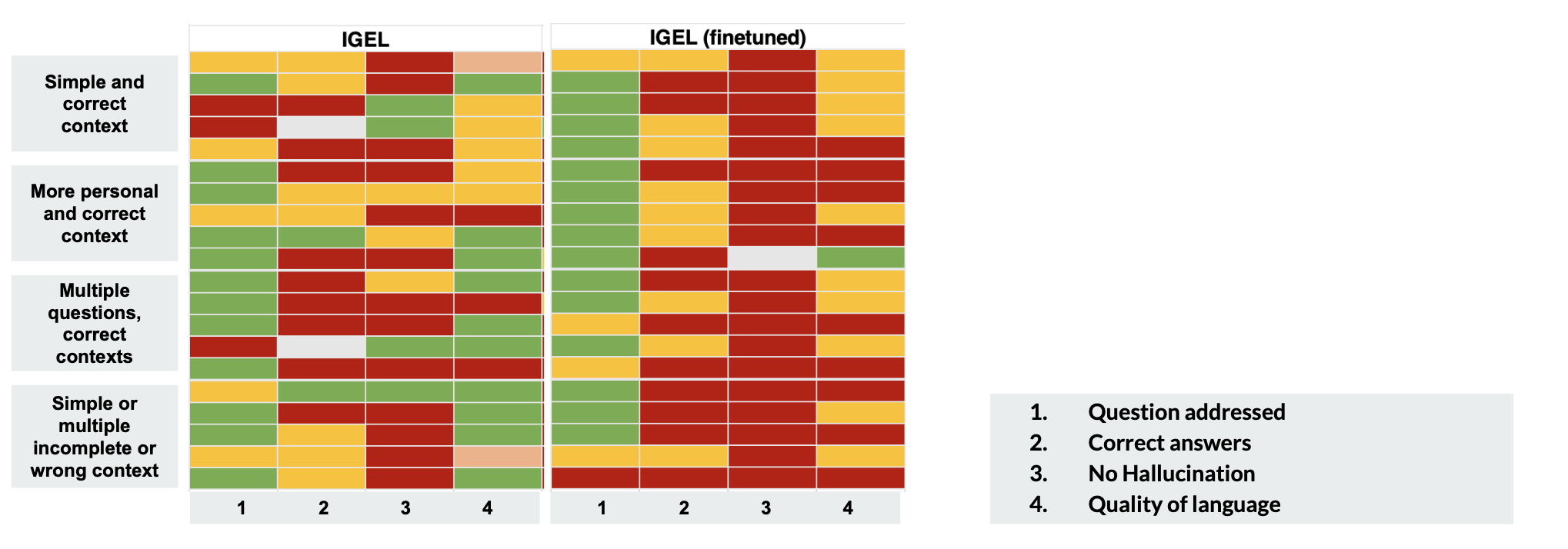
Base models’ comparison
More results coming soon…
Download data
Translated data
Automatically generated test emails (appr. 350) with Openai
Raw QA on FAQ
QA on all data
Generated E-mails (with given context)